Propósito: El trabajo busca establecer un proceso automatizado de curación semántica, que permita alcanzar una clara descripción ontológica de lo expuesto en los textos científicos.
Metodología: A partir de una demarcación epistémica, basada en un marco un marco concreto, constituido por: una comunidad científica, una sociedad anfitriona, un dominio del discurso; y un marco conceptual integrado por: un trasfondo filosófico, un trasfondo formal, un trasfondo específico, un trasfondo acumulado, una problemática, un objetivo, y una metódica. Además se realiza una demarcación de los datos aplicando la marcación RDFa, estructurada según Schema.org, que será de utilidad para la indexación en IA.
Resultados: se logra desarrollar un modelo para llevar adelante un proceso de curación a textos científicos que puede ser sintetizado bajo la tripleta: sujeto, predicado, objeto de la Web Semántica establecida por Tim Berners-Lee.
Conclusiones: La inclusión de curación académica y asistida por IA en los artículos científicos fortalecerá su utilidad para la indexación semántica y la interacción con sistemas de IA. La mayor relevancia de esta propuesta, es la de entregar los elementos necesarios que permiten constituir un proceso de aprendizaje para la Inteligencia Artificial.
Abstract
Purpose: The work seeks to establish an automated semantic curation process, which allows to achieve a clear ontological description of what is presented in scientific texts.
Methodology: Starting from an epistemic demarcation, based on a concrete framework consisting of a scientific community, a host society, a domain of discourse; and a conceptual framework made up of: a philosophical background, a formal background, a specific background, an accumulated background, a problem, an objective, and a method. In addition, a delimitation of the data is carried out by applying the RDFa markup, structured according to Schema.org, which will be useful for indexing in AI.
Results: a model is developed to carry out a curation process for scientific texts that can be synthesized under the triplet: subject, predicate, object of the Semantic Web established by Tim Berners-Lee.
Conclusions: The inclusion of academic and AI-assisted curation in scientific articles will strengthen their usefulness for semantic indexing and interaction with AI systems. The greatest relevance of this proposal is to provide the necessary elements that allow for the constitution of a learning process for Artificial Intelligence.
1. Introduction
El trabajo busca desarrollar un sistema de información dirigido por académicos bajo el «Modelo PRC»: Publicar – Revisar – Curar; con foco en la «curación de contenidos»; más particularmente una «curación digital» que provea información relevante a la web, a través de metadatos ontológicos y semánticos. Consecuentemente, la metódica sistemática propuesto permitirá: identificar, evaluar, e interpretar trabajos de investigación en un campo de conocimiento científico determinado. (Scholarly publisher, 2023)
Con ello se espera enriquecer el proceso educativo, entre docentes y estudiantes, en un marco denominado: Entorno Personal de Aprendizaje (PLE por sus siglas en inglés: Personal Learning Environment), el cual se ve constituido por las siguientes actividades:
buscar y seleccionar la información de interés;
organizar los contenidos;
comunicarse con los demás, a través de una Red Personal de Aprendizaje (PLN por sus siglas en inglés: Personal Learning Network), y constituir un espacio de ciencia participativa (participatory sciences);
crear nuevos contenidos bajo el modelo Linked Open Data;
publicarlos para compartirlos con la comunidad científica (community science); y
colaborar comunitariamente (citizen science) en tareas de producción científica y académicas.
2. Demarcación ontológica
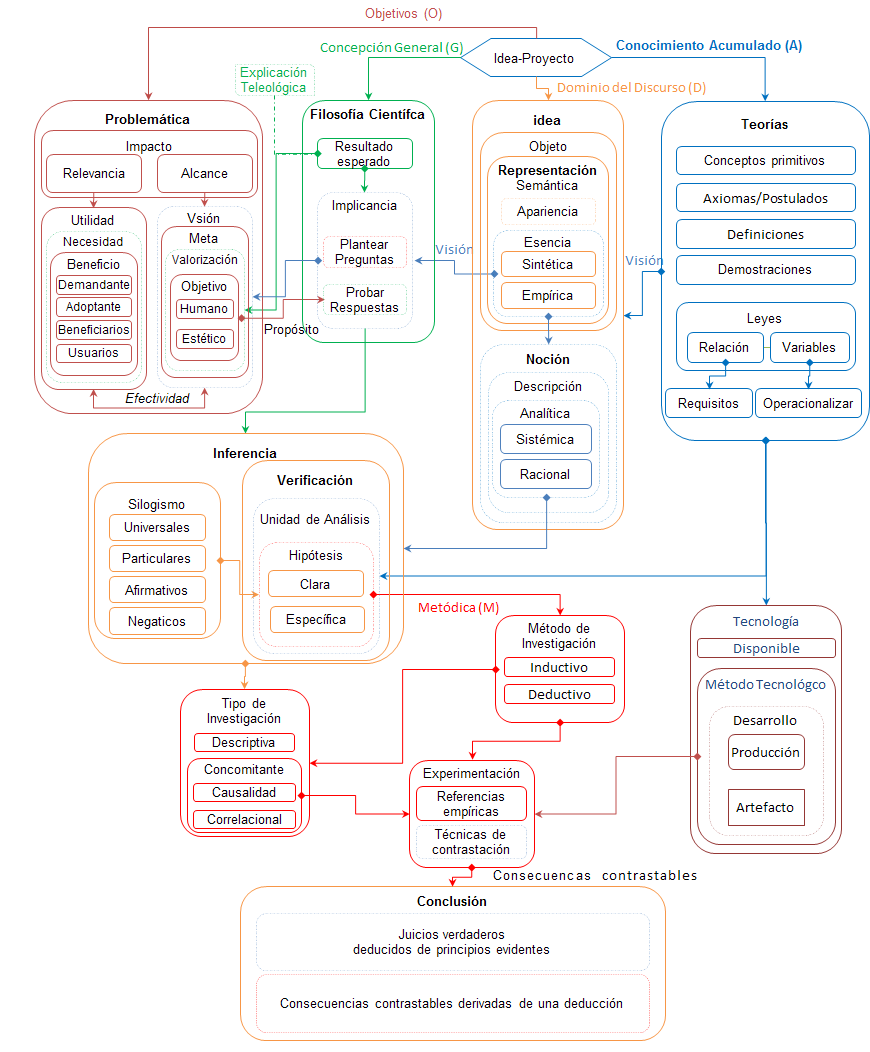
Siguiendo a Mario Bunge (Seudociencia e ideología, pág. 45), vemos que toda Idea Proyecto se establece en el dominio de un campo de investigación; y éste último, debe ser analizado desde un marco material y un marco conceptual, a saber:.
El marco material, representado por la tritupla Em = « C, S, D », compuesto por:
C = una comunidad de sujetos investigadores;
S = una sociedad anfitriona que alberga a dicha comunidad, apoyando o participando de sus actividades; y
D = un dominio del discurso sobre un objeto de estudio, de entes reales certificados o presuntos, en un determinado contexto.
El marco conceptual en un campo epistémico dado, puede caracterizarse como una séptupla Ec = « G, F, E, A, P, O, M » donde:
G = concepción general o trasfondo filosófico, constituido por: una ontología, una gnoseología y un ethos; todos ellos, inherentes al dominio del discurso;
F = trasfondo formal, de lógica teórica o matemática para realizar y sustentar inferencias válidas;
E = trasfondo específico, constituido por conocimientos (datos, teoremas, hipótesis) tomados en préstamo de "campos de conocimiento" lindantes;
A = bagaje acumulado de conocimientos verdaderos y eficaces, como colección al día de: teorías, leyes, modelos o hipótesis; obtenidos en investigaciones previas;
O = un objetivo, como finalidad última de la investigación, que permite describir, explicar, y predecir hechos; como así también, validar teorías y leyes.
M = una metódica (congruente con el objeto y la hipótesis), por el que se pueda saber y justificar procedimientos y resultados.
Respecto al trasfondo específico (E), que Charles Peirce (Escritos filosóficos, pág. 103-107) expone que: la idea de una ciencia, depende de otra, en los principios fundamentales; en el mismo sentido Ernest Mach (Conocimiento y error, pág. 18), dice que los resultados en otras ramas del conocimiento deben contribuir a orientar al científico, en su propio campo del conocimientos o especialidad; y será esta fusión en las especialidades la que aportará a la concepción de una «cosmovisión» hacia la cual tienden todos los especialistas.
Consecuentemente, como condición necesaria, toda Idea Proyecto debe estar especificada por la siguiente sextupla Ip = « D, G, A, P, O, M », donde:
D = Objeto de estudio en un determinado contexto;
G = Un andamiaje o filosofía inherente, que permita constituir una concepción racional o visión general del objeto de estudio;
A = colección al día de evidencias y principios, representados a través de las referencias bibliográficas citadas.
P = Una problemática sobre el objeto de estudio, semánticamente descripta a través de claras proposiciones o hipótesis.
O = un objetivo, como resultado a priori del problema, que conjuntamente indican la metodología a seguir para resolver dicho problema.
M = una metódica, por la que se pueda alcanzar y contrastar los resultados.
Este es el contenido de la etiqueta Figure de diseñoIdea-Proyecto, perspectiva sistémica de una problemática a investigar <
3.
Curación
Concretamente, la curación a seguir realizada se hará aplicando la demarcación epistemológica presentada, lo cual permitirá valorar un trabajo científico para la web semántica.
Estructura de un cuerpo científico: Lenguaje científico y la construcción de modelos y teorías.
Donde Ln = Lenguaje Natural; Lt = Lenguaje Teórico
Comunidad de sujetos investigadores (Community Science)
Campos de conocimiento disciplinares, establecido por la actuación de la comunidad de investigadores, que conforman la línea de investigación. La denominación, surgida de las subjects (en algunos casos por las key words), surge de aplicar de un sistema taxonómico, tal es el UNESCO Thesaurus, enumerando así el término general, el particular, y algunos otros relacionales si correspondiera.
subject 1:
subject 2:
subject 3:
Sociedad anfitriona que apoya y participa como ciencia ciudadana (Crowdsourcing-Citizen Science)
Cuáles son las personas, agrupaciones gubernamentales, industriales, o sociales que contribuyen colaborativamente (Crowdsourcing), con la investigación, y quienes participan más activamente (Citizen Science) en en todas o en algunas de las etapas de la investigación; estableciendo una Investigación-Acción. Ver caso
Dominio del Discurso: Objeto de estudio
Establecido por la principal idea sustanciada en evidencias relevantes que permite distinguir y comprender, en esencia, al objeto de estudio; y cúal es el conjunto de datos (Dataset) que sustenta dichas evidencias.
Concepción general: Trasfondo Filosófico
Cuál es la cosmovisión o el conjunto de conceptos utilizados que modelan, de manera rigurosa, el dominio del discurso; y por el cual se plantea el problema y explora la respuesta.
Cosmovisión o conjunto de conceptos utilizados que modelan, de manera rigurosa, el dominio del discurso; y por el cual se plantea el problema y explora la respuesta.
Conocimiento: Trasfondo Formal
Cómo se referencia o representa, desde la lógica o la matemática, al objeto de estudio.
Conocimiento: Trasfondo Específico
Cuál es el conocimiento específico en que se basa el estudio, como ser teorías, leyes, teoremas, axiomas, principios, o modelos aceptados por los cuales se referencia o representa al objeto de estudio.
Conocimiento: Trasfondo Acumulado
Cuál es el bagaje acumulado de conocimientos obtenidos previamente por los miembros de la comunidad de investigadores.
Problemática
Cuál es el planteo concreto o hipótesis, mediante el cual se presenta al problema.
Objetivo
Cuál es el propósito del estudio (como fin último en referencia a la naturaleza del objeto de estudio), cuál es el objetivo o meta (como resultado a priori) que se persigue, y cuáles son sus implicancias.
Metódica: métodos utilizados
Qué tipo de metodología se aplica para resolver el problema de investigación.
Resultados
Cuáles son las principales evidencias; en lo posible expresadas como conjunto de dato (Dataset) surgentes del estudio; y cuál es el principal resultado que concuerda con el objetivo.
Conclusión
Cuál es la deducción resultante de las consecuencias contrastables, provista por el prinipal hallazgo (resultado); y cuál es su implicancia o aporte al campo del conocimiento (Bagaje Acumulado).
Bibliografía
Establecer la validación de las citas realizadas pautando su relevancia (citation).
4.
Marcación semántica para web en Resource Description Framework (RDF)
El método consiste en expresar la información como una lista de sentencias bajo la forma de una tripleta: Sujeto-Predicado-Objeto; donde el sujeto y el objeto son nombres para dos cosas en el mundo y el predicado es el nombre de la relación entre esas cosas.
En nuestro caso los nombres en las sentencias RDF se usan para referir recursos (Recordando el uso que se le daba a RDF para metadatos en la web).
for each sentencia in conocimienot{
if (sentencia.sujeto == pregunta.sujeto or pregunta.sujeto == what)
if (sentencia.predicado == pregunta.predicado or pregunta.predicado == what)
if (sentencia.objeto == pregunta.objeto or pregunta.objeto == what)
callRespuesta(sentencia)
for each sentencia in conocimienot{
if (sentencia.sujeto == pregunta.sujeto or pregunta.sujeto == what)
if (sentencia.predicado == pregunta.predicado or pregunta.predicado == what)
if (sentencia.objeto == pregunta.objeto or pregunta.objeto == what)
callRespuesta(sentencia)
Una posible regla podría ser (ChatGPT):
Premisa 1: Si un documento tiene un name y un author, entonces es un artículo.
Premisa 2: Si un artículo tiene un datePublished, es un artículo publicado.
Conclusión: Si un documento tiene name, author y datePublished, entonces es un artículo publicado con metadatos completos.